Running Pipelines
- How to Run a Pipeline
- Specifying Variables for a Pipeline Run
- Specifying Variables for a Job
- About Jobs
- Job Triggers
- Running a Pipeline on a Schedule
- Incoming Webhook Job Trigger
- Disabling Jobs
- Getting Outputs From a Run
- Suppressing Output From a Run
- Masking Secrets in Run Events
- Queueing Multiple Runs
- Automatic Retry of a Failed Run
Running a Pipeline queues up the run and makes it available to Runners, which acquire the run, execute it, and report detailed log information back to the application.
How to Run a Pipeline
There are two main ways a Pipeline can be run:
- Directly on the Pipeline page, by clicking the Run button.
- Using a Job.
Input data can be provided to a Pipeline in the form of variables. Output data can be obtained from run output.
Specifying Variables for a Pipeline Run
Pipelines can have variables that allow you to provide values for Pipeline Step Modules.
If a Pipeline has input variables, these will appear in the run dialog when someone runs your Pipeline so that they can override these values, if desired. Variables marked as hidden will not appear in run dialogs and their values can’t be changed at runtime. If a Pipeline variable is marked as default, then the value specified in the Pipeline will fill in for values omitted from the Job at runtime. For more about variable configuration, see Variable Configuration.
Specifying Variables for a Job
On a Job page, under Pipeline Configuration, you may set values for the Pipeline variables that are separate and independent from values specified by the Pipeline. This allows you to have Jobs that target the same Pipeline revision but that use different variables.
Note
It’s possible to create or update a Job and leave all the variable values empty, even if some or all of those variables are required by the Pipeline. This is because values may be provided at runtime.
If, however, any values are provided, this will trigger a validation that checks to see that all the variables are correct. In this case, you will need to provide values for any variables required by the Pipeline.
About Jobs
While Pipelines can be run directly, you can also create one or more Jobs. These enable more sophisticated control over how and when a Pipeline runs. A Job is like a “run configuration” for a Pipeline. It defines which Pipeline revision to run, the input variable values to use, a trigger type, and runtime settings for a Pipeline run.
Job Triggers
Jobs can be triggered in one of three ways:
- Manually, by clicking the Run button on the Job page;
- On a Schedule; and
- By an Incoming Webhook.
Running a Pipeline on a Schedule
To run a Pipeline on a schedule, create a Scheduled Job. On the Jobs page, click New Job. In the dialog, select Scheduled for the trigger type, and then fill out the schedule fields.
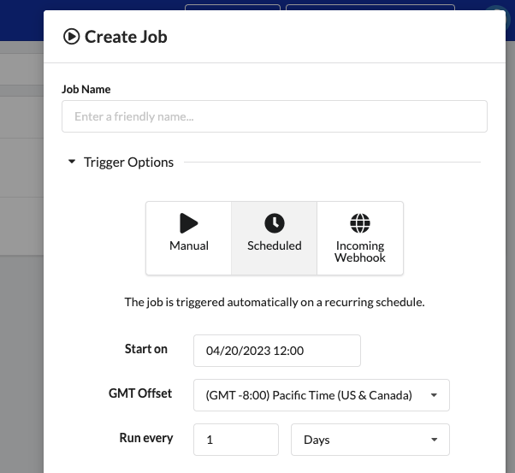
For a scheduled Job to run, it needs an available Runner assigned to the associated Project. If your Project doesn’t have any Runners, Jobs will fail to create runs. This prevents the scheduler from creating a backlog of queued runs which are flushed all at once when the Runner is started.
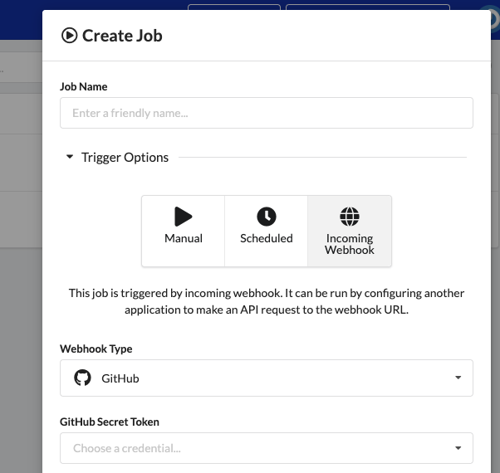
Incoming Webhook Job Trigger
Jobs can be configured with an Incoming Webhook trigger type, which enables powerful integrations with other systems that fire webhook events. For example, you can configure a Job to run a Pipeline every time a commit is made to a git repository on GitHub or GitLab.
See here for more information about webhooks in general.
To create an Incoming Webhook Job, visit the Jobs page from the main navigation and then click New Job. In the dialog, select Incoming Webhook for the trigger type, and then optionally fill out the webhook fields. These fields can be changed after the Job is created.
Note
- Incoming Webhooks only support JSON request bodies. The
Content-Typeof Incoming Webhook requests should beapplication/json. - Many features of Sophos Factory expressions are not supported in webhooks, including the
read_file()helper and the filesystem test functions. Webhook expression evaluation is highly isolated and does not have access to a full operating system like it does inside a Runner. - Webhook expressions must evaluate quickly. Attempting to process large amounts of data in an Incoming Webhook request may cause that request to be terminated and return an error code.
Incoming Webhook Jobs have several powerful features for transforming and validating the input request.
Transforming Input Variables
The Variables Transform field is an expression which can be used to dynamically create the input variables for a Pipeline run from the webhook request. For example, for a Pipeline with a single string variable called my_string, we could use this expression for the variables transform:
{
"my_string": "some literal value"
}
This example “hard codes” the value of the variable my_string. Often we’ll want to instead compute the value of this variable from the incoming request data. For example, if the external system sends a JSON body like this:
{
"company": {
"id": "5"
}
}
We can extract the company id into the my_string variable using this expression:
{
"my_string": body.company.id
}
In addition to body, we can also use the headers object to access the incoming request headers. Headers are converted to lowercase, so if the company id is instead provided in a X-Company-Id header, we can access it using this expression:
{
"my_string": headers["x-company-id"]
}
Validating Incoming Requests
Credentials and Project variables are also available in webhook expressions, which is useful for performing custom authentication. Let’s say our external system adds an X-Auth-Token header to webhook requests, and we want to validate that this token equals a secret value.
- Add a credential to the Project with type API Token, and enter the secret token in the Token field. Let’s say the credential ID is
my_cred. - In the webhook Job, use the following expression in the Validator field to check that the
X-Auth-Tokenheader matches the credential value:
credential("my_cred").token == headers["x-auth-token"]
Project variables can be accessed using the vars. syntax, so an equivalent validator can be created by using a Project variable instead:
vars.my_cred == headers["x-auth-token"]
Some webhook systems use basic authentication. To validate these requests, use the Credential field of a webhook Job. This field should be a username/password type of credential. The parsing of the username and password is performed automatically behind the scenes, so you don’t need to write an expression for this case.
Finally, for systems that don’t provide an authentication mechanism, you can configure an IP whitelist for a webhook Job. Any requests not matching the whitelisted IPs will be rejected with a 401 status code.
Controlling the Webhook Response
Since some systems require that webhook endpoints return specific status codes, you can override the success status code in the Job. This code will be returned if the webhook successfully executed, which may not mean that the request created a run, for example if the Condition expression evaluated to false. To force an Incoming Webhook to always return a specific status code, even when errors occur, you can turn on the Ignore Errors field.
Disabling Jobs
When a Job is disabled, it will never run, even if it has a scheduled trigger type. The Run button will be disabled in the application, and calls to the API will return an error code.
Scheduled Jobs can also be configured to be automatically disabled when any runs fail.
Getting Outputs From a Run
After a Pipeline is finished executing, its evaluated outputs are available from the run history page as well as from the API.
To view outputs from the application, open the run from the Run History page, then select Outputs from the dropdown at the top.
Suppressing Output From a Run
If you’d like to prevent the Runner from sending any detailed data about the run back to the application, you can configure a Job to suppress its reporting.
- Suppress variables: The input variables are only stored temporarily until the Runner begins executing the run, and then they are deleted. Run variables will not be available from the run page.
- Suppress outputs: Pipeline outputs will not be sent to the application by the Runner.
- Suppress events: The detailed event log from the run will not be sent to the application by the Runner. Note that this can make it difficult to debug Pipeline runs, but it also ensures that no step output logs leave the Runner.
With all three of these settings enabled, the Runner will only send metadata about the run to the application, which creates a high degree of data isolation on the Runner. This is useful when your Pipelines are working with highly sensitive data, and you don’t want this data ever reaching the Sophos Factory servers.
Masking Secrets in Run Events
All credential and SecureString variable values will be automatically masked in any run events. If the secret appears in run event logs, it will be replaced by *****. This helps prevent sensitive data from leaking into your run history.
When a secret value contains multiple lines of text, each line is treated as a single secret. While this reduces the chances of a multiline secret avoiding the masking routine, it can also result in over-masking. For example, if your secret contains formatted JSON, then the first line will be {, which causes all instances of { to be replaced with *****, which might not be what you want. To work around this problem, simply enter JSON secrets as a single line.
Queueing Multiple Runs
When many runs are created quickly, they are placed into a queue to be processed by available Runners. When no Runners are assigned to a Project, or there are not enough Runners to process the runs, the maximum run queue length will eventually be reached. When the queue is full, you will no longer be able to create new runs from the application or API.
Automatic Retry of a Failed Run
When a Pipeline or Job is run manually, there is an option to automatically retry the run if it fails. In Advanced Options, the value labeled Automatic retry on failure controls this feature.
The value of this option determines whether the run will be automatically retried when it fails. By default, the value is empty meaning that the run will not be retried automatically when it fails.
By entering a value greater than zero, the user can request that the run be automatically retried when it fails up to the number of retries specified. The maximum number of retry attempts that can be requested is 99. If the user enters a value of 10 and the run fails, then the run will be retried up to 10 additional times resulting in a total of up to 11 runs (the original and up to 10 retries).
When a run completes, it will be automatically retried when all of the following are true.
- The Run Status is Failed.
- The maximum number of retry attempts was entered when the run was started.
- The maximum number of retry attempts has not yet been reached.
- The run was started from a Job and the Job is not currently disabled.
- The run queue is not full.
The automatic run retries may stop before the maximum number of retries is reached when any of the following are true.
- The run queue is full when a run – the original or an automatic retry – was being submitted.
- The Run Status of the last completed run is Successful.
- The Run Status of the last completed run is Canceled.
- The run was started from a Job and the Job has been disabled.
The Automatic retry on failure option is available in the following screens.
- When running a Job or Pipeline manually, the value for the current run can be specified.
- Run Job
- Run Pipeline
- Run Catalog Pipeline
- For manually-triggered Jobs, a default value can be stored in the Job and, optionally, overridden when run.
- Create Job
- Edit Job
The Automatic retry on failure option is not available in the following screens.
- When manually retrying a run.
- Run Detail. The Retry button starts a manual retry of the run, not an automatic retry. Automatic run retries are not allowed here regardless of the setting on the original run.